
Stephanie Jauss

KI im Audiobereich – Teil 2:
Eine Audio-KI-Lösung entwickeln, Anwendungsbereiche und Beispiele

Diese Reihe besteht aus ‘Teil 1: Grundlagen der Signalverarbeitung und Audio-Features für Machine Learning’ und ‘Teil 2: Eine Audio-KI-Lösung entwickeln, Anwendungsbereiche und Beispiele’.
Im ersten Teil dieser Serie haben wir uns die Grundlagen der Signalverarbeitung und typische Audio-Features für Machine Learning angeschaut. Im zweiten Teil lernen wir nun einige frei verfügbare Technologien kennen, die einen guten Ausgangspunkt bilden, um eine eigene KI-Lösung im Audiobereich zu entwickeln. Um solch einen Anwendungsfall in Zukunft erkennen zu können, schauen wir uns außerdem beispielhafte Use Cases aus unterschiedlichen Branchen an, in denen Audiodaten Teil einer KI-Lösung wurden.
Eine Audio-KI-Lösung entwickeln
Wenn Sie einen Anwendungsfall erkannt haben, in denen die Anwendung von KI im Kontext von Audiodaten erfolgreich sein könnte, haben Sie zwei Möglichkeiten:
1) Vorhandene Modelle nutzen
Oft müssen Sie nicht bei null anfangen, sondern können vorhandene Ressourcen nutzen. Es lohnt sich also eine Recherche nach existierenden Modellen, vor allem Open-Source-Modelle, die kostenlos und ohne Datenschutzbedenken nutzbar sind. Zu typischen Machine-Learning-Aufgaben veröffentlichen insbesondere die großen Firmen im IT- und KI-Bereich immer wieder Algorithmen, die auf riesigen Datenmengen trainiert wurden und daher gut generalisieren. Besonders bei nicht so stark spezialisierten Anwendungsfällen bietet es sich an, solche erprobten Algorithmen einzusetzen, zumal man viel Zeit, Expertise und Hardware benötigt, um ein solches Modell selbst zu trainieren.
So veröffentlichte zum Beispiel erst im September 2022 die Firma OpenAI das Open-Source-Spracherkennungsmodell „Whisper“, das auf einem Encoder-Decoder-Transformer basiert und auf 680.000 Stunden Sprachaufnahmen in mehreren Sprachen trainiert wurde. Die Eingabe erfolgte in Form von Mel-Spektrogrammen, die wir bereits kennengelernt haben. Neben Transkription (Speech-to-Text), können die nach Größe abgestuften Modelle auch Spracherkennung und Übersetzung ins Englische vornehmen. Auf GitHub finden Sie Benchmark-Angaben zu den verschiedenen Sprachen sowie Anleitungen zu Installation und Verwendung der Modelle, die mit steigender Größe bessere Ergebnisse liefern, allerdings auch mehr Rechenleistung und Zeit benötigen.
Ich habe die Modelle anhand eines deutschen Podcast-Ausschnitts getestet und konnte diesen in guter Qualität transkribieren. Darüber hinaus habe ich auf dieselbe Aufnahme das Open-Source-Tool „pyannote“ angewandt, das Audio nach Sprecher*innen in Segmente unterteilt. Auch dies hat sehr gut funktioniert, jedoch ist entsprechende Hardware mit GPUs empfehlenswert, um die Laufzeit zu verringern.
Die Kombination aus Spracherkennung und Sprecher*innentrennung (speaker diarization/segmentation) könnte für mehrere Use Cases interessant sein, beispielsweise zum automatischen Erstellen von Protokollen/Transkripten. Eine solche Implementierung würde nicht einmal tiefere Machine-Learning-Kenntnisse erfordern und durch die Quelloffenheit ist Datenhoheit garantiert.
Dieses Beispiel zeigt außerdem, dass die Kombination mehrerer Technologien oft sinnvoll sein kann. Es lohnt sich daher, auch über den Tellerrand hinauszuschauen, welche Anwendungsbereiche es im Machine-Learning – im oder außerhalb des Audiobereichs – gibt. So ist nach einer Transkription zum Beispiel die Anwendung von Modellen aus dem Bereich Natural Langauge Processing (NLP) denkbar: Übersetzung, Zusammenfassung (Summarization) eines Texts, das Extrahieren von relevanten Schlüsselwörtern (Keyword Extraction) oder ähnliche.
Eine gute Anlaufstelle für Modelle, Datensätze und weiterführende Informationen ist die KI-Community Huggingface. Deren Website bietet zum Beispiel einen Überblick über typische Aufgaben, die Machine-Learning-Modelle übernehmen können, auch für den Audiobereich. Für jeden dieser Tasks bekommt man eine englischsprachige Übersicht, um was es geht, sowie beispielhafte Use Cases, Bibliotheken, Code, Modelle, Datensätze und mehr, wie Abb. 1 zeigt.
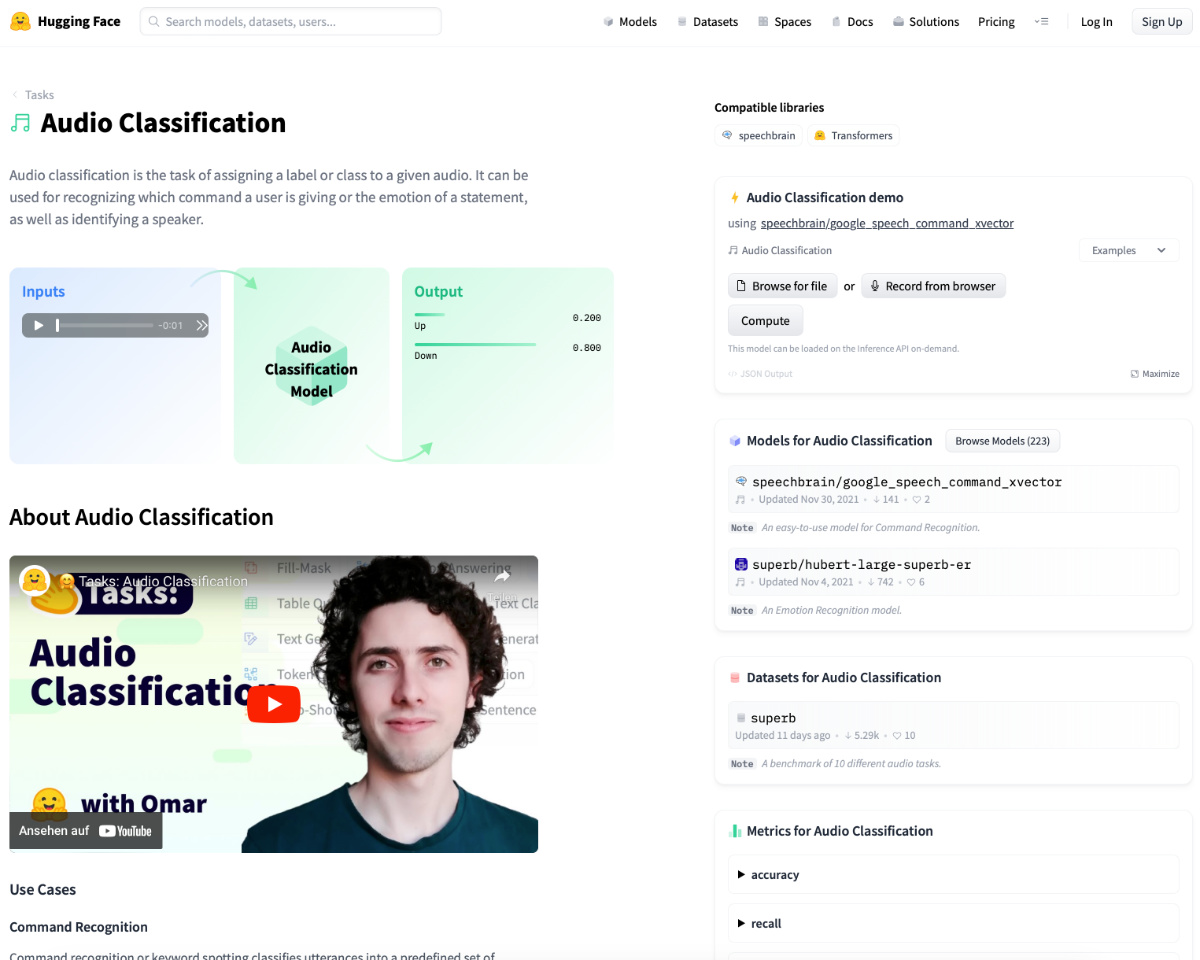
Abb. 1: Screenshot der Huggingface-Website für den Task ‘Audio Classification’.
Quelle: https://huggingface.co/tasks/audio-classification
User laden außerdem oft ihre trainierten Modelle auf Huggingface hoch, die beispielsweise auf Grundlage eines bekannten Modells mit einer bestimmten Aufgabe als Ziel weitertrainiert und so spezialisiert (Transfer Learning) oder anhand einer vorhandenen Architektur auf bestimmten Daten neu trainiert wurden (Fine Tuning).
2) Ein eigenes Modell trainieren
Sollten Sie für Ihre Anwendung kein passendes existierendes Modell finden, können Sie natürlich auch ein eigenes Modell trainieren. Da das Sammeln und Vorverarbeiten der Daten oft den größten Aufwand bedeutet, lohnt es sich je nach Use Case, nach vorhandenen Daten zu suchen. Dafür gibt es mehrere Datenbanken online, zum Beispiel Kaggle oder wie bereits erwähnt Huggingface.
Alternativ können Daten selbst erhoben oder im Unternehmen bereits vorhandene Daten kombiniert werden. Bei überwacht gelernten Algorithmen, beispielsweise ein neuronales Netz für Klassifikation, werden neben der gewählten Repräsentation des Audios für die Eingabe außerdem gekennzeichnete (gelabelte) Daten benötigt. Der Prozess der Kennzeichnung kann sehr aufwendig sein, aber es gibt einige Tools, die das Labeln beschleunigen und angenehmer machen. Ein webbasiertes Tool, das auch in einer Open-Source-Version zur Verfügung steht, ist Label Studio. Es bietet bereits Templates für zahlreiche typische ML-Tasks, unter anderem für das Labeln von Audiodaten, wie Abb. 2 zeigt.
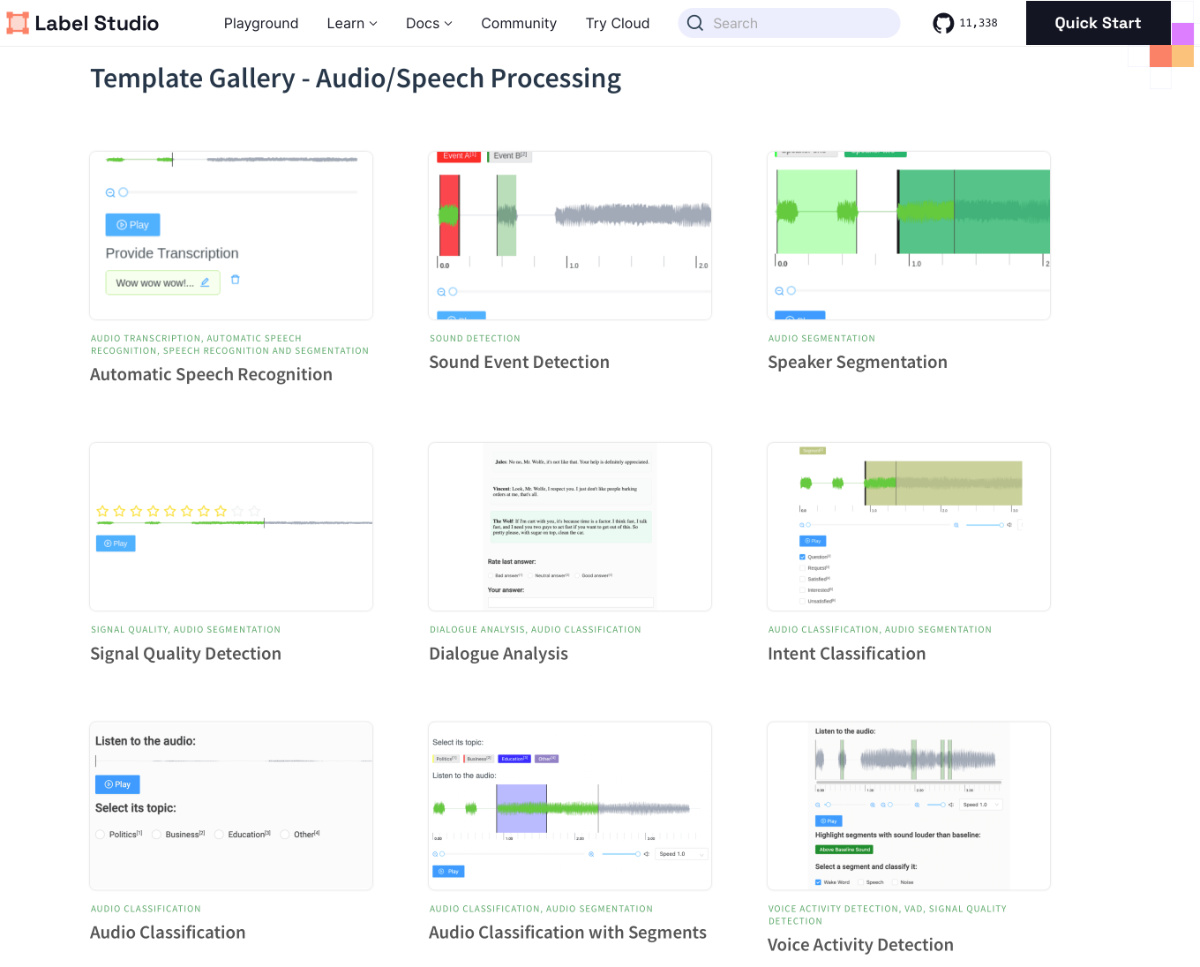
Abb. 2: Label Studio Template-Gallerie für den Audiobereich.
Quelle: https://labelstud.io/templates/gallery_asr.html
Liegen die Daten schließlich vor, gibt es wie oben beschrieben die Möglichkeit, ein vorhandenes Modell durch Transfer Learning oder Fine Tuning anzupassen. Oder aber man probiert selbst unterschiedliche Modellarten und -architekturen aus. Für die technische Umsetzung eignen sich die bekannten Machine-Learning-Bibliotheken sowie spezielle Libraries für den Audiobereich wie Librosa oder PyTorch.
KI im Audiobereich – Anwendungsbereiche & Beispiele
Audio umgibt uns im Alltag in verschiedenen Formen: Stimme, Sprache, Musik, Geräusche aus der Natur wie Tiergeräusche oder auch menschengemachte Geräusche wie von Autos oder Maschinen. Die folgende List zeigt eine Bandbreite an KI-Use-Cases im Audiobereich aus unterschiedlichen Branchen, grob kategorisiert in die zugrundeliegende Aufgabenart.
Audio-Erkennung und -Klassifikation

- Stimmanalysen mithilfe von KI könnten in Zukunft neben der Transkription eine zusätzliche Ebene an Informationen schaffen, zum Beispiel durch eine automatische stimmbasierte Emotionsanalyse, um Notrufaufnahmen oder Kundenanfragen noch besser zu priorisieren.
- Darüber hinaus können Machine-Learning-Modelle heutzutage allein auf Basis einer Stimmaufnahme immer mehr über eine Person herausfinden, zum Beispiel Geschlecht und Alter, sodass die Nutzung unter anderem in der forensischen Kriminalistik sicherlich zunehmen wird.
- Dass eine KI-Stimmanalyse sogar Krankheiten diagnostizieren kann, vermuten Forscher*innen des Projekts „Voice as a Biomarker of Health“, an dem unter anderem die Universität Montréal beteiligt ist. Es gebe Hinweise darauf, dass unsere Stimme sich nicht nur bei Atemwegs- oder Lungenerkrankungen verändert, sondern auch Rückschlüsse auf neurologische Krankheiten wie Alzheimer oder psychische Erkrankungen wie Depression zulässt. Entsprechende Machine-Learning-Modelle sollen nun entwickelt werden.
- Durch die Corona-Pandemie wurde auch an nicht-invasiven Diagnostikverfahren für Covid-19 auf Basis von Machine Learning geforscht. Forscherinnen unter anderem vom MIT und von der University of Cambridge trainierten erfolgreich Classifier auf der Basis von Tonaufnahmen von Husten-, Atemgeräuschen oder der Stimme gesunder und infizierter Patientinnen. Die Modelle erreichten eine Sensitivität und Spezifität im Bereich von 70 bis über 90 Prozent. Weitere Anwendungen im Gesundheitsbereich sind beispielsweise die Schnarcherkennung oder die auditive Überwachung von Patienten oder Babys.
- Forschung gibt es auch im Bereich der automatischen audiobasierten Erkennung und Verhinderung von häuslicher Gewalt, Gewalt im Auto oder Kriminalität im öffentlichen Raum. Geräuscherkennung kommt dabei ähnlich zum Einsatz wie bei Sicherheits- und Alarmsystemen in modernen Smart Homes, die gefährliche Geräusche wie beim Einschlagen eines Fensters oder einen Brand erkennen können.
- Geräuscherkennung kann auch im Alltag für gehörlose oder schwerhörige Personen nützlich sein. Daher bieten zum Beispiel iPhones seit iOS 14 die Möglichkeit, in den Bedienungshilfe eine Geräuscherkennung zu aktivieren, um bei bestimmten Geräuschen wie einer Sirene, einer Türklingel, einem weinenden Baby oder einem selbst definierten Geräusch benachrichtigt zu werden.
- Auch Maschinen in der Industrie erzeugen häufig Geräusche, aus denen Expert*innen Rückschlüsse ziehen können. Kann das in Zukunft eine KI? Das Projekt IDMT-ISAAC des Fraunhofer-Instituts für Digitale Medientechnologie beschäftigt sich mit der Entwicklung eines Qualitätssicherungstools, das Industriegeräusche auswertet, um zum Beispiel Fehler in der maschinellen Fertigung automatisch zu erkennen. Bosch setzt eine ähnliche Technologie namens SoundSee auf der internationalen Raumstation ISS ein und sieht weitere Anwendungsfälle in der Industrie, Gebäudesicherheit, im Automobilbereich oder Gesundheitswesen. Der Bereich, unübliches Verhalten zu erkennen, wird auch als Anamoly Detection bezeichnet.
- Die Non-Profit-Organisation Rainforest Connection hat ein ähnliches Verfahren im Bereich Naturschutz entwickelt: Ein Abhörnetz aus alten Handys wurde in Regenwäldern installiert, um Waldgeräusche aufzuzeichnen. Mithilfe von Machine Learning werden Geräusche klassifiziert und so unübliche Geräusche wie Kettensägen oder Lastwagen identifiziert, die auf illegale Abholzung hindeuten können. So können solche Aktivitäten schneller erkannt werden, um zu intervenieren und den Regenwald zu schützen. Auf ähnliche Weise werden im Natur- und Tierschutz außerdem Tierarten automatisch anhand ihrer Geräusche erkannt, um beispielsweise den Bestand zu überwachen, eine Bedrohung frühzeitig zu erkennen oder illegale Jagd zu verhindern.
- Neben Stimme und Geräuschen gibt es einen weiteren Anwendungsbereich: Musik. Tools wie Shazam ermöglichen es, aufgezeichnete Songs zu identifizieren. Weitere Use Cases sind die automatische Erkennung von Instrumenten, Genre oder Stimmung eines Songs sowie Clustering ähnlicher Musik. Solche Techniken kommen zum Beispiel in Apps wie Spotify zum Einsatz, die uns so Musik nach unserem Geschmack empfehlen können. In der Videobearbeitung können außerdem Video- und Audioanalysen kombiniert werden, um passende Songs zu finden oder die Synchronisierung von Video und Tonspur zu erleichtern.
Audio-Transkription
- Stimm- und Spracherkennung in Assistenzsystemen sind die Klassiker. Sie kennen sicherlich Siri, Alexa, Google Home oder ähnliche Systeme im Auto. Diese können mithilfe von KI Ihre Sprachbefehle verstehen und im Fall von Stimmerkennung auch erkennen, wer gerade spricht. Die Transkription von Sprachaufnahmen (Speech to Text), wie bereits im Kontext von Whisper erwähnt, ist ein Use Case, der in zahlreichen Branchen und Bereichen Einsatz findet. Unter anderem im Kundenservice wird oft bereits KI eingesetzt, um Anrufe automatisch zu transkribieren und anschließend zum Beispiel zu kategorisieren.
- Neben der automatischen Transkription von Diktaten, Meetings oder Telefonaten im Kundenservice ist Transkription auch im Bereich Barrierefreiheit wichtig. Die Erzeugung automatischer Untertitel kennt man online schon lange, zum Beispiel von YouTube. Mit derselben Technologie wurden darüber hinaus Apps entwickelt, die bei Gesprächen in Lautsprache Gesagtes in Echtzeit in Textform umwandeln oder Untertitel für den Kinobesuch erzeugen.
- Im Gesundheitswesen hat man das Potenzial jetzt teilweise ebenfalls erkannt. Das Unternehmen Corti zum Beispiel hat auf der Basis von Audioaufnahmen einer dänischen Notrufhotline ein ML-Modell trainiert, das schneller und verlässlicher als die Notrufmitarbeitende Fälle von Herzstillstand erkennen kann, indem es das Gesagte in Echtzeit auswertet.
- Neben Sprache gibt es Transkription auch für Musik. Mehrere kommerzielle Anbieter versprechen, Musikaufnahmen automatisch in Noten für verschiedene Instrumente umzuwandeln, zum Beispiel das Karlsruher Start-up Klangio mithilfe von Deep Learning.
Audio-Segmentierung, -Analyse und -Erzeugung

- Die Unterteilung von Sprachaufnahmen in Sprecher*innen haben wir bereits kennengelernt. Diese kann nicht nur in Verbindung Transkription nützlich sein. So wird einem zum Beispiel im virtuellen Klassenzimmer der Sprachlernapp „Preply“ sein eigener Redeanteil in einem Gespräch angezeigt.
- Eine andere Art der automatischen Echtzeit-Audioanalyse verwenden seit Kurzem ARD und ZDF, um Zuschauer*innen die Tonspur „Klare Sprache“ anzubieten. Das KI-Modell analysiert dafür den Ton nach Sprachanteilen und kann so die Lautstärke von Hintergrundgeräuschen und Musik verringern.
- Das britische Unternehmen Flawless AI geht noch weiter und bietet TrueSync Dubbing an. Dabei werden Lippenbewegungen in Videos an den gesprochenen Synchrontext angepasst, mit dem Ziel, synchronisierte Filme realistischer aussehen zu lassen.
- Im Musikbereich wird ebenso wie im Sprachbereich KI genutzt, so können etwa Gesang und Instrumente getrennt werden. Damit kann man zum Beispiel aus jedem beliebigen Song eine Karaokeversion erzeugen.
- In den letzten Jahren entwickelt sich insbesondere der Bereich der KI-basierten Audioerzeugung rasant weiter. 2020 veröffentlichte OpenAI Jukebox, ein neuronales Netz, das Musik generieren kann. Dabei können Genre, Stil einer bestimmten Interpretin bzw. eines bestimmten Interpreten oder der Songtext vorgegeben werden. Die Ergebnisse, räumen die Forscher*innen jedoch selbst ein, klingen noch nicht genauso wie von Menschen geschaffene Musik.
- Im Bereich Spracherzeugung gibt es ebenfalls fortlaufend Verbesserungen. Erst im Oktober stellte Google AudioLM vor, das einen Audio-Clip von wenigen Sekunden Länge erstaunlich realistisch vervollständigen kann, und das sowohl für Klaviermusik als auch für Sprache. Die Beispiele kann man sich auf der zugehörigen GitHub-Seite anhören. Bei der Spracherzeugung werden die Sprachmerkmale desder originalen Sprecherin wie Dialekt, Rhtythmus und Klangfarbe beibehalten. Aber auch inhaltlich vervollständigt die KI den Satzanfang mehr oder weniger sinnhaft. Ein großer Vorteil des neuen Modells ist, dass es rein audiobasiert ist, während bei vorherigen Modellen wie Jukebox zusätzliche semantische Informationen für das Training notwendig sind, zum Beispiel transkribierte Texte. Das funktioniert, indem AudioLM mithilfe von w2v-BERT selbstüberwacht semantische Charakteristiken (wie bei Sprache Phonetik und Syntax) als auch mit dem Audio-Codec SoundStream die auditiven Charakteristiken der Stimme versteht. Gleichzeitig wird die künstlich erzeugte Sprache dadurch realistischer, da linguistische Informationen, die nicht in Text ausgedrückt und daher bei reinen Text-to-Speech-Modellen nicht berücksichtigt werden, stärker beachtet werden, zum Beispiel Nebengeräusche oder Atempausen.
- Das Klonen von echten Stimmen ist ein Use Case, den ein solches Modell bietet. Bereits 2018 hat Google in einem Projekt, dessen Beispiele man sich ebenfalls anhören kann, die Stimmen von echten Personen anhand nur fünf Sekunden langer Audioaufnahmen täuschend echt geklont. Ein ähnliches Verfahren verwendet wohl auch Amazon, denn erst vor wenigen Monaten kündigten sie an, den Alexa-Sprachassistenten mit echten Stimmen personalisieren zu können. Die Ankündigung war kontrovers, da in einem Werbespot ein Kind fragte, ob „Oma“, also Alexa als die verstorbene Großmutter, etwas vorlesen könne.
- Neben solchen seltsamen bis unterhaltsamen Anwendungen wie eine Personalisierung von Assistenzsystemen bietet Stimmnachahmung aber natürlich auch ein großes Potenzial für Betrug. 2019 wurde ein Fall einer britischen Firma bekannt. Der Firmenchef erhielt einen Anruf, scheinbar vom Chef der Muttergesellschaft, mit Bitte um Überweisung von 220.000 Euro, der er folgte. Doch der Anrufer war nicht der Chef, es wurde lediglich dessen Stimme künstlich nachgeahmt. Mit zunehmender Verbreitung von immer realistischer klingenden und personalisierbareren Technologien zur Spracherzeugung steigt die Gefahr für solche Betrugsfälle.
All diese Beispiele zeigen, dass der Bereich KI für Audio groß und vielfältig ist. Sicherlich gibt es noch viele weitere spannende KI-Technologien aus dem Audiobereich und auch in Zukunft werden sich durch neue technische Entwicklungen noch ganz neue Möglichkeiten bieten. Jedoch sollte man dabei ethische Überlegungen nicht außer Acht lassen.
Um KI-Anwendungsfälle im Audiobereich im eigenen Umfeld aktiv zu erkennen, hilft es, sich einige Vorteile zu verdeutlichen. Die Interaktion mit Audiosystemen ist dort besonders interessant, wo die haptische Bedienung durch körperliche Einschränkungen wie zum Beispiel eine Sehbehinderung oder Kleidung nicht möglich ist. Auch die Datenerfassung bietet im Audiobereich Vorteile: Mikrofone werden von Dunkelheit oder anderen Lichtverhältnissen nicht beeinflusst, können auch an Orten eingesetzt werden, wo Kameras nicht eingebaut werden können, und sind in der Regel günstiger. Audiodaten können offensichtlicher Informationsträger sein, zum Beispiel bei Sprache oder Musik, aber sie können auch dort nützlich sein, wo man es vielleicht zunächst nicht erwartet, zum Beispiel in der medizinischen Diagnostik.
Fazit
Sie verstehen nun die Grundlagen der Signalverarbeitung für Audio im KI-Bereich sowie typische Audio-Features und wissen, wie Sie bei der Entwicklung einer eigenen KI-Lösung im Audiobereich vorgehen können. Sie haben vielfältige Anwendungsbeispiele aus unterschiedlichen Branchen kennengelernt. Vielleicht entwickeln Sie inspiriert davon auch bald in Ihrem Umfeld eine KI-Anwendung im Audiobereich.
Quellen
- https://openai.com/blog/whisper/
- https://github.com/openai/whisper
- https://github.com/pyannote/pyannote-audio
- https://www.covid-19-sounds.org/de/blog/detect_covid_kdd.html
- Exploring Automatic COVID-19 Diagnosis via Voice and Symptoms from Crowdsourced Data. Jing Han, Chloe Brown, Jagmohan Chauhan, Andreas Grammenos, Apinan Hasthanasombat, Dimitris Spathis, Tong Xia, Pietro Cicuta, Cecilia Mascolo. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2021) doi.org/gc25
- Sounds of COVID-19: exploring realistic performance of audio-based digital testing. Jing Han, Tong Xia, Dimitris Spathis, Erika Bondareva, Chloe Brown, Jagmohan Chauhan, Ting Dang, Andreas Grammenos, Apinan Hasthanasombat, Andres Floto, Pietro Cicuta, Cecilia Mascolo. In Nature Digital Medicine (npj Digit. Med.), 2022 doi.org/hfcz
- https://www.embs.org/ojemb/articles/covid-19-artificial-intelligence-diagnosis-using-only-cough-recordings/
- https://www.huawei.com/de/deu/magazin/kuenstliche-intelligenz/mit-ki-gegen-rodungen
- https://rfcx.org/impact
- https://www.healthcaredenmark.dk/toolbox/danish-solutions/corti/
- https://www.resuscitationjournal.com/article/S0300-9572(18)30975-4/fulltext
- https://www.ijcaonline.org/archives/volume176/number25/debnath-2020-ijca-920214.pdf
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8434188/
- https://www.nytimes.com/2022/04/05/technology/ai-voice-analysis-mental-health.html
- https://www.wired.co.uk/article/audio-analytics-sound-map
- https://support.apple.com/de-de/guide/iphone/iphf2dc33312/ios
- https://schwerbehindertenausweis.biz/kuenstliche-intelligenz-hilft-menschen-mit-behinderung/
- https://vocalremover.org/de/
- https://www.heise.de/hintergrund/Google-KI-hoert-Musik-und-Sprache-und-komponiert-und-spricht-weiter-7287271.html
- https://www.golem.de/news/alexa-amazon-will-tote-sprechen-lassen-2206-166356.html
- https://www.golem.de/news/social-engineering-mit-kuenstlicher-intelligenz-220-000-euro-erbeutet-1909-143638.html
- https://www.wsj.com/articles/fraudsters-use-ai-to-mimic-ceos-voice-in-unusual-cybercrime-case-11567157402