

Selected Topics #1: Adversarial Attacks
Tutorial: Adversarial Examples Against Image Recognition
Deep neural networks (DNNs) are becoming increasingly popular and successful in various areas of machine learning. Some exemplary applications of deep learning are image recognition, speech recognition and natural language processing. Thanks to their versatility, such deep learning techniques are also used in areas where safety and security are of critical concern. From autonomous driving to breast cancer diagnostics and even government decisions, deep learning methods are increasingly used in high-stakes environments. Thus, the security of deep neural networks has become a central issue - and a problem: Welcome to the domain of adversarial attacks!
This tutorial is an introduction into the theory and practice of adversarial attacks, especially in the domain of image recognition. You will learn
- what adversarial examples are and how to create them,
- what damage adversarial examples can cause in image recognition tasks,
- how to implement digital and physical attacks against image recognition,
- how to implement adversarial attacks against both white- and black-box models,
- how you can defend your own image recognition models against adversarial attacks.
Introduction: Adversarial Attacks
Contents
Prerequisites
Basic Theory
The tutorial uses different models and methods of deep learning, such as convolutional neural networks (CNNs) and autoencoders. It assumes that you already have an understanding of these methods, so the basics won’t be covered in great detail. If you’d like to read up on these technologies in advance, you can take a look at the online resources we’ve listed below.
Some previous knowledge on the TensorFlow and Keras libraries is helpful, but we will cover the necessary code in full detail.
Python, Tensorflow and Keras
To avoid any compatibility problems due to different versions we recommend to use the same Python and Keras version as we do. However it is mandatory to use a 1.x version of Tensorflow, because in Tensorflow 2 some things are different. Again we recommend to use the same version we used for this tutorial.
- Python : 3.7
- Tensorflow: 1.14
- Keras: 2.3.1
Motivation
In contrast to traditional machine learning techniques, which require much domain knowledge and manual feature engineering, deep neural networks (DNNs) are often described as end-to-end learning algorithms. The models use raw data directly as input to the model and learn its underlying structures and attributes.
The nature of many DNNs makes it easy for adversaries generate high-quality deceptive inputs, also known as adversarial examples. Ian Goodfellow et al. described them in the OpenAI blog:
Adversarial examples are inputs to machine learning models that an attacker has intentionally designed to cause the model to make a mistake; they’re like optical illusions for machines.[4]
Intuition: Decision Boundaries
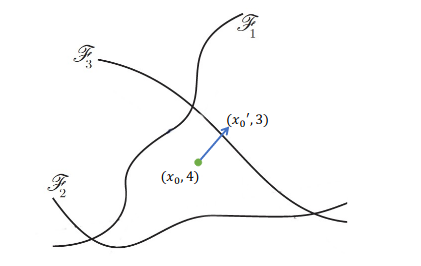
The key concept of adversarial examples is to deceive a model’s internal decision boundaries. During training, a (deep) neural network learns decision boundaries, which determine its behavior. These boundaries are represented by the network’s parameters. If an adversary finds out where the decision boundaries are, they can change the input examples in such a way that “pushes” them over the boundary. Figure 1 illustrates this process on the example of a classifier model: There, the input $x_0$ is manipulated, so that the machine learning model classifies the adversarial $x_0\mathtt{'}$ differently (class 3 instead of class 4).
Adversarial attacks are a technical possibility in virtually all areas of deep learning. To give some examples: BERT-Attack[6] is a successful attack against Google’s deep language model BERT (Bidirectional Encoder Representations from Transformers). Other attacks work by altering sound data to fool automatic speech recognition applications.[7]
Finally, this tutorial is a deep-dive on adversarial attacks against image-recognition. Computer vision lends itself well to a visual tutorial like this one, and there is a good amount of research available on such methods as well.
To give you an overview on the practical implementation of such adversarial attacks, as well as a method countermeasure them, we have implemented different attacks and defenses across four chapters.
Threat Model [4]
To understand such attacks and assess their risk, it is helpful to define a threat model. This describes in what way and with what knowledge the attacker attacks and what goal they are pursuing. The threat model in adversarial attacks can be divided into the adversary’s goal and the adversary’s knowledge.
Adversary’s Goal
Poisoning Attack or Evasion Attack
- Poisoning attacks refer to the attack algorithms that allow an attacker to insert/modify multiple counterfeit samples into the training database of a DNN algorithm. These fake samples can lead to failures of the trained classifier. That can then result in poor accuracy or wrong prediction. This type of attacks frequently appears in a situation where the adversary has access to the training database. For example, if a spammer has access to the training database of an “intelligent” spam filter, they might label their emails as “not spam” and add them to the training pool, so that the filter learns to ignore such spam emails.
- Evasion attacks assume that the target model is already trained and has reasonably good performance on benign test examples. The adversary does not have authority to change the architecture or its parameters. Instead, they craft some fake examples that the classifier cannot recognize correctly. The attacks covered in this tutorial are all evasion attacks.
Targeted Attack or Untargeted Attack
- Targeted attacks pursue the goal of influencing the model to predict a previously defined class. The model should therefore predict a certain class through the adversarial example.
- Untargeted attacks do not have a target class which it wants the model to classify the image as. Instead, the goal is simply to make the target model misclassify by predicting the adversarial example, as a class, other than the original class.
Digital Attack or Physical Attack
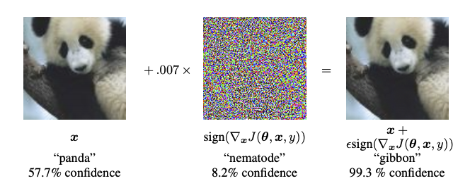
- Digital attacks add some minimal noise to the input image . This noise is invisible to the human eye, but it affects the target model in such a way that it assigns a wrong class to that image (Figure 2).
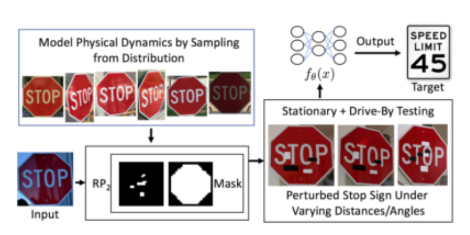
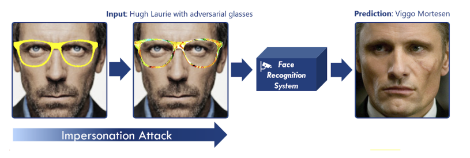
- Physical attacks modify real objects to make the target misclassify them (Figure 3 + Figure 4). In these cases, the input of the model is an image captured by sensor (for example a camera). This enables very practical real-world attacks (e.g. on autonomous driving or face recognition systems).
Adversary’s Knowledge
To describe the attacker’s knowledge, a distinction is made between black-box, gray-box and white-box.

White Box Attacks
In a white-box setting, the adversary has access to all the information of the target neural network, including its architecture, parameters, gradients etc. They can make full use of the network information to carefully craft adversarial examples.
Methods for white-box Attacks:
- Jacobian-based Saliency Map Attack (more details)[11]
- Carlini-Wagners Attack (more details)[12]
- Szegedys SL-BFGS Attack (more details)[13]
- Fast Gradient Sign Method - FGSM - (used in our tutorial)
- Projected Gradient Descent - PGD (used in our tutorial)
Black Box Attacks
In a black-box attack setting, the inner configuration of the target DNN models is unavailable to adversaries. Adversaries can only feed the input data and query the outputs of the models. The usual approach is to create some substitute model, that can generate the adversarial samples instead. Compared to white-box attacks, black-box attacks are more practical in applications. Model designers usually don’t make their model parameters available, due to proprietary reasons.
Methods for black-box attacks:
- Zeroth Order Optimization Based Black-box Attack (more details)[14]
- Substitute Model (used in our tutorial)
Gray Box Attacks (semi-white)
In a gray-box attack, the attacker has some knowledge about the target DNN model, but doesn’t see everything. They also train a model for producing adversarial examples. This model could, for example, be a Generative Adversarial Network that can craft adversarial examples directly. Once this model is trained, the attacker does not need the target model anymore and can craft adversarial examples in the same way as in a black-box setting. In this tutorial, you will only encounter white- and black-box attacks.
Methods for gray-box attacks:
- GAN-Attacks (more details)[15]
Countermeasures [5]
In order to protect the security of deep learning models, different strategies have been considered as countermeasures against adversarial examples. There are basically three main categories of these countermeasures:
- Gradient masking/obfuscation: Masking or hiding the gradients will confound the adversaries. So you try to turn a white box into a black box by hiding information. Example methods for gradient masking are Defensive Destillation or Shattered Gradients.
- Robust optimization: Robust optimization methods aim to improve the robustness of the classifier by changing the training routine of the DNN model. They investigate how model parameters can be learned that can provide promising predictions for potential adversarial examples. Example methods are Adversarial Re-Training or regularization.
- Adversarial examples detection: Adversarial example detection is another main approach to protect DNN classifiers. Instead of predicting the model’s input directly, these methods first distinguish whether the input is adversarial. Then, if it can detect that the input is adversarial, the DNN classifier will refuse to predict its label. Such methods include Defense-GANS [18] or different kinds of autoencoders.
We have decided to implement a very up-to-date detector approach using autoencoders when implementing a countermeasure. This approach is based on “Matching Prediction Distributions” and presented in this paper from February 2020.[19]
Chapter Overview
Great, you are now ready to start with the implementation! To get the most out of this tutorial, you should follow the chapters in order, because they are cumulative. Start with the easiest one, the digital attack, then try the physical attack before you take a closer look at the black-box attack and finally at the countermeasures.
Chapters: Adversarial Attacks & Countermeasures
In our tutorial notebooks we define the same adversarial goal for all chapters: To cause an image classifier to misclassify the input samples. You’ll implement the corresponding evasion attacks and test targeted and untargeted-attacks for each different method. Note the differences in the knowledge of the attacker and the used dataset. To countermeasure such attacks and to detect adversarial examples, we try the described detector approach, which you implement in the last chapter.
| Chapter | Knowledge | Methods | Dataset |
|---|---|---|---|
| Chapter 1: Digital Attack | White-Box | FGSM + PGD | STL10 |
| Chapter 2: Physical Attack | White-Box | FGSM | STL10 |
| Chapter 3: Black-Box Attack | Black-Box | Substitute Model | MNIST |
| Chapter 4: Countermeasure with Autoencoder Detection | Detector | STL10 |
Used Datasets
In the tutorials, two different datasets are used to show the respective attacks. For the digital and physical attack, you will use the STL-10 dataset and for the black-box attack, due to the increased complexity, you’ll use the MNIST dataset:
- STL-10: The STL-10 dataset is an image recognition dataset for developing supervised and unsupervised feature learning, deep learning and self-taught learning algorithms. It is inspired by the CIFAR-10 dataset, but with higher resolution (96x96 pixels) and slightly modified classes (airplane, bird, car, cat, deer, dog, horse, monkey, ship, truck).

- MNIST: The MNIST database (Modified National Institute of Standards and Technology database) is a large dataset, which consists of handwritten digits from 0-9 and is used in our black-box tutorial.

Conclusion
Hopefully, after working through the tutorials you’ve now gained an understanding of the adversarial attacks that can be used against machine learning models. The gradient based attacks have shown you how easily and quickly an attacker can generate images, if he is in possession of the model. Even the FGSM method, where the perturbation is calculated only once, leads to very good results in untargeted attacks. With the PGD attack, even targeted attacks with hardly visible noise are possible. That it is possible to print out calculated perturbations in any form and still deceive the model should be clear to you after the second chapter. A naive solution is to think that if you don’t make your model architecture and trained weights publicly available, you are on the safe side, but as you saw in the Black-Box attack, this step is not enough. Very promising are the introduction of additional models, like a second classification model or an autoencoder, which are switched in front of the actual model and protect it by either directly recognizing adversarial images or, as in our case, trying to filter out perturbation. You saw how well this worked in the last chapter.
This tutorial can however only provide the tiniest glimpse of what’s possible: There are many, many ways in which machine learning methods can be used against each other. While this tutorial only covers image recognition scenarios, the topic of adversarial attacks touches almost every area of machine learning. New papers on attacks and defenses are constantly appearing, some voices even call it an arms race.
The current state-of-the-art attacks will likely be neutralized by new defenses, and these defenses will subsequently be circumvented.
Xu et al. 2019: Adversarial Attacks and Defenses in Images, Graphs and Text: A Review[5]
Such research is vital for the continued success of deep learning, especially in critical systems where failure can be fatal. It will likely be a long time before the issue of adversarial attacks is solved entirely. Adversarial examples exist due to an inherent limitation in deep learning as it exists today:
These results suggest that classifiers based on modern machine learning techniques, even those that obtain excellent performance on the test set, are not learning the true underlying concepts that determine the correct output label. Instead, these algorithms have built a Potemkin village that works well on naturally occurring data, but is exposed as a fake when one visits points in space that do not have high probability in the data distribution.
Goodfellow et al. 2015: Explaining and Harnessing Adversarial Examples[20]
Machine learning models as of yet have no real understanding of the data they observe. All it takes to confuse them are examples that wouldn’t naturally occur, because the models would have no idea how to process them. There is no definitive fix to cover all possible attacks. The space of possible adversarial examples is simply too large to catch them all. If we want to truly fix this flaw, it will probably require another milestone in machine learning research. So, to end this tutorial on a positive note, let’s finish with another quote from that same paper:
We regard the knowledge of this flaw as an opportunity to fix it.[20]
Further Ideas
In our tutorial we gave you a small and simplified insight into the complex world of adversarial attacks and their countermeasures. If you’ve made it this far and would like to learn even more, you can find information about adversarial attacks and countermeasures (also with code examples and tutorials) at the links below. These are great code repositories created to aid in the understanding of and defense against adversarial attacks.
Sources
[1] Neural Networks and Deep Learning
[2] A Comprehensive Guide to Convolutional Neural Networks
[3] Implementing Autoencoders in Keras: Tutorial
[4] OpenAI blog - Attacking Machine Learning
with Adversarial Examples
[5] Adversarial Attacks and Defenses in Images, Graphs and Text: A Review
[6] BERT-ATTACK: Adversarial Attack Against BERT Using BERT
[7] Adversarial Attacks Against Automatic SpeechRecognition Systems via Psychoacoustic Hiding
[8] Robust Physical-World Attacks on Deep Learning Visual Classification
[9] Robustifying Machine Perception for Image Recognition Systems: Defense Against the Dark Arts
[10] Easy Examples for Black, White and Gray Box Testings
[11] The Limitations of Deep Learning in Adversarial Settings
[12] Towards Evaluating the Robustness of Neural Networks
[13] Intriguing properties of neural networks
[14] ZOO: Zeroth Order Optimization Based Black-box Attacks toDeep Neural Networks without Training Substitute Models
[15] Generating Adversarial Examples with Adversarial Networks
[16] Tensorflow - stl10
[17] The MNIST database
[18] Defense-GAN: Protecting Classifiers Against Adversarial Attacks Using Generative Models
[19] Adversarial Detection and Correction by Matching Prediction Distributions
[20] Explaining and Harnessing Adversarial Examples
[21] cleverhans GIT-Repository
[22] IBM adversarial-robustness-toolbox